We provide 70-774 Exam Dumps which are the best for clearing 70-774 test, and to get certified by Microsoft Perform Cloud Data Science with Azure Machine Learning (beta). The 70-774 Free Practice Questions covers all the knowledge points of the real 70-774 exam. Crack your Microsoft 70-774 Exam with latest dumps, guaranteed!
Also have 70-774 free dumps questions for you:
NEW QUESTION 1
You have an Execute R Script module that has one input from either a Partition and Sample module or a Web service input module.
You need to preprocess tweets by using R. The solution must meet the following requirements:
How should you complete the R code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: 
NEW QUESTION 2
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this scries.
Start of repeated scenario
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services. The experiment for fraud prediction will use Machine Learning modules and APIs to train the models and will predict probabilities in an Apache Hadoop ecosystem.
End of repeated scenario.
You plan to share the Machine Learning workspace with the other users.
You are evaluating whether to assign the User role or the Owner role to several of the users.
Which three actions can be performed by the users who are assigned the User role? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Create, open, modify, and delete datasets.
- B. Create, open, modify, and delete experiments.
- C. Invite users to the workspace.
- D. Delete users from the workspace.
- E. Create, open, modify, and delete web services.
- F. Access notebooks.
Answer: CDF
NEW QUESTION 3
You are building an Azure Machine Learning workflow by using Azure Machine Learning Studio. You create an Azure notebook that supports the Microsoft Cognitive Toolkit.
You need to ensure that the stochastic gradient descent (SGD) configuration maximizes the samples per second and supports parallel modeling that is managed by a parameter server.
Which SGD algorithm should you use?
- A. DataParallelASGD
- B. DataParallelSGD
- C. ModelAveragingSGD
- D. BlockMomentumSGD
Answer: C
NEW QUESTION 4
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services. The experiment for fraud prediction will use Machine Learning modules and APIs to train the models and will predict probabilities in an Apache Hadoop ecosystem.
End of repeated scenario.
You need to alter the list of columns that will be used for predicting fraud for an input web service endpoint. The columns from the original data source must be retained while running the Machine Learning experiment.
Which module should you add after the web service input module and before the prediction module?
- A. Edit Metadata
- B. Import Data
- C. SMOTE
- D. Select Columns in Dataset
Answer: D
NEW QUESTION 5
You have the following HiveQL query in an Import Data module.
Which type of operation is being performed?
- A. sampling a bucketized table
- B. random sampling by groups
- C. uniform random sampling
- D. stratified sampling
Answer: D
NEW QUESTION 6
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Machine Learning workflow.
You have a dataset that contains two million large digital photographs. You plan to detect the presence of trees in the photographs.
You need to ensure that your model supports the following:
Solution: You create a Machine Learning experiment that implements the Multiclass Neural Network module. Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 7
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You plan to use Azure platform tools to detect and analyze food items in smart refrigerators. To provide families with an integrated experience for grocery shopping and cooking, the refrigerators will connect to other smart appliances, such as stoves and microwave ovens, on a LAN.
You plan to build an object recognition model by using the Microsoft Cognitive Toolkit. The object recognition model will receive input from the connected devices and send results to applications.
The training data will be derived from more than 10 TB of images. You will convert the raw images to the sparse format.
End of repeated scenario.
You need to ensure that a web service endpoint can receive image data and use an object recognition model to return the expected object and the confidence level of the model. The solution must minimize the effort required to generate the client code to access the web service.
Which resource should you use?
- A. the edX Data Science Learning Dashboard
- B. Azure Machine Learning Studio
- C. Cortana Intelligence Gallery
- D. the Data Science Virtual Machine
Answer: B
NEW QUESTION 8
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You plan to use Azure platform tools to detect and analyze food items in smart refrigerators. To provide families with an integrated experience for grocery shopping and cooking, the refrigerators will connect to other smart appliances, such as stoves and microwave ovens, on a LAN.
You plan to build an object recognition model by using the Microsoft Cognitive Toolkit. The object recognition model will receive input from the connected devices and send results to applications.
The training data will be derived from more than 10 TB of images. You will convert the raw images to the sparse format.
End of repeated scenario.
The image files to train the object recognition model are stored in a Microsoft SQL Server 2021 Standard edition database on an Azure virtual machine (VM).
You need to support R packages that can use full parallel threading and processing for RevoScaleR.
How should you implement R? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.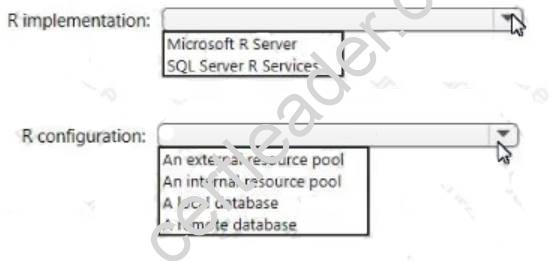
Answer:
Explanation: 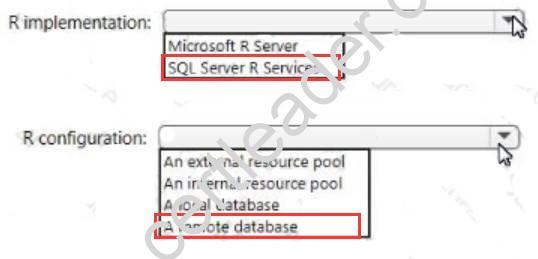
NEW QUESTION 9
You are working on an Azure Machine Learning experiment that uses four different logistic regression algorithms. You are evaluating the algorithms based on the data in the following table.
Which model produces predictions that are the closest to the actual outcomes?
- A. Model 1
- B. Model 2
- C. Model 3
- D. Model 4
Answer: A
NEW QUESTION 10
Note: This question is part of a series of questions that use the same or similar answer choices. An
answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You need to change a column name to a friendly name. The solution must use a native module. Which module should you use?
- A. Normalize Data
- B. Select Columns in Dataset
- C. Import Data
- D. Edit Metadata
- E. Tune Model Hyperparameters
- F. Clean Missing Data
- G. Clip Values
- H. Execute Python Script
Answer: D
NEW QUESTION 11
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a non-tabular file that is saved in Azure Blob storage.
You need to download the file locally, access the data in the file, and then format the data as a dataset. Which module should you use?
- A. Execute Python Script
- B. Tune Model Hyperparameters
- C. Normalize Data
- D. Select Columns in Dataset
- E. Import Data
- F. Edit Metadata
- G. Clip Values
- H. Clean Missing Data
Answer: E
Explanation: References:
https://msdn.microsoft.com/en-us/library/azure/mt674698.aspx
NEW QUESTION 12
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Machine Learning workflow.
You have a dataset that contains two million large digital photographs. You plan to detect the presence of trees in the photographs.
You need to ensure that your model supports the following:
Solution: You create a Machine Learning experiment that implements the Multiclass Decision Jungle module. Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 13
You need to identify which columns are more predictive by using a statistical method. Which module should you use?
- A. Filter Based Feature Selection
- B. Principal Component Analysis
- C. Group Data into Bins
- D. Tune Model Hyperparameters
Answer: B
NEW QUESTION 14
You are building an Azure Machine Learning experiment.
You need to transform a string column into a label column for a Multiclass Decision Jungle module. Which module should you use?
- A. Select Columns Transform
- B. Group Categorical Values
- C. Convert to Indicator Values
- D. Edit Metadata
Answer: D
NEW QUESTION 15
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
A travel agency named Margie’s Travel sells airline tickets to customers in the United States.
Margie’s Travel wants you to provide insights and predictions on flight delays. The agency is considering implementing a system that will communicate to its customers as the flight departure nears about possible delays due to weather conditions. The flight data contains the following attributes:
The weather data contains the following attributes: AirportID, ReadingDate (YYYY/MM/DD HH), SkyConditionVisibility, WeatherType, WindSpeed, StationPressure, PressureChange, and HourlyPrecip.
You need to use historical data about on-time flight performance and the weather data to predict whether the departure of a scheduled flight will be delayed by more than 30 minutes.
Which method should you use?
- A. clustering
- B. linear regression
- C. classification
- D. anomaly detection
Answer: C
Explanation: References:
https://gallery.cortanaintelligence.com/Experiment/Binary-Classification-Flight-delay-prediction-3
NEW QUESTION 16
The manager of a call center reports that staffing the center is difficult because the number of calls is unpredictable. You have historical data that contains information about the calls.
You need to build an Azure Machine Learning experiment to predict the number of total calls each hour. Which model should you use?
- A. Multiclass Logistic Regression
- B. Boosted Decision Tree Regression
- C. Decision Forest Regression
- D. Poisson Regression
Answer: D
100% Valid and Newest Version 70-774 Questions & Answers shared by Certleader, Get Full Dumps HERE: https://www.certleader.com/70-774-dumps.html (New 64 Q&As)