Want to know Certleader DEA-C01 Exam practice test features? Want to lear more about Snowflake SnowPro Advanced: Data Engineer Certification Exam certification experience? Study High value Snowflake DEA-C01 answers to Abreast of the times DEA-C01 questions at Certleader. Gat a success with an absolute guarantee to pass Snowflake DEA-C01 (SnowPro Advanced: Data Engineer Certification Exam) test on your first attempt.
Online Snowflake DEA-C01 free dumps demo Below:
NEW QUESTION 1
Which system role is recommended for a custom role hierarchy to be ultimately assigned to?
- A. ACCOUNTADMIN
- B. SECURITYADMIN
- C. SYSTEMADMIN
- D. USERADMIN
Answer: B
Explanation:
The system role that is recommended for a custom role hierarchy to be ultimately assigned to is SECURITYADMIN. This role has the manage grants privilege on all objects in an account, which allows it to grant access privileges to other roles or revoke them as needed. This role can also create or modify custom roles and assign them to users or other roles. By assigning custom roles to SECURITYADMIN, the role hierarchy can be managed centrally and securely. The other options are not recommended system roles for a custom role hierarchy to be ultimately assigned to. Option A is incorrect because ACCOUNTADMIN is the most powerful role in an account, which has full access to all objects and operations. Assigning custom roles to ACCOUNTADMIN can pose a security risk and should be avoided. Option C is incorrect because SYSTEMADMIN is a role that has full access to all objects in the public schema of the account, but not to other schemas or databases. Assigning custom roles to SYSTEMADMIN can limit the scope and flexibility of the role hierarchy. Option D is incorrect because USERADMIN is a role that can manage users and roles in an account, but not grant access privileges to other objects. Assigning custom roles to USERADMIN can prevent the role hierarchy from controlling access to data and resources.
NEW QUESTION 2
A Data Engineer is investigating a query that is taking a long time to return The Query Profile shows the following: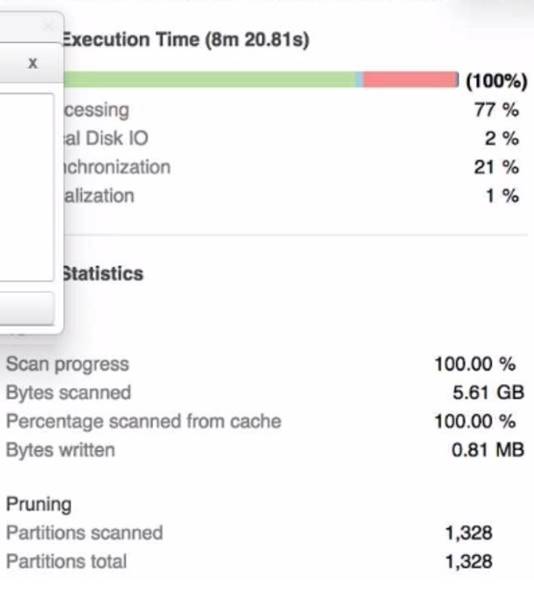
What step should the Engineer take to increase the query performance?
- A. Add additional virtual warehouses.
- B. increasethe size of the virtual warehouse.
- C. Rewrite the query using Common Table Expressions (CTEs)
- D. Change the order of the joins and start with smaller tables first
Answer: B
Explanation:
The step that the Engineer should take to increase the query performance is to increase the size of the virtual warehouse. The Query Profile shows that most of the time was spent on local disk IO, which indicates that the query was reading a lot of data from disk rather than from cache. This could be due to a large amount of data being scanned or a low cache hit ratio. Increasing the size of the virtual warehouse will increase the amount of memory and cache available for the query, which could reduce the disk IO time and improve the query performance. The other options are not likely to increase the query performance significantly. Option A, adding additional virtual warehouses, will not help
unless they are used in a multi-cluster warehouse configuration or for concurrent queries. Option C, rewriting the query using Common Table Expressions (CTEs), will not affect the amount of data scanned or cached by the query. Option D, changing the order of the joins and starting with smaller tables first, will not reduce the disk IO time unless it also reduces the amount of data scanned or cached by the query.
NEW QUESTION 3
A Data Engineer wants to check the status of a pipe named my_pipe. The pipe is inside a database named test and a schema named Extract (case-sensitive).
Which querywill provide the status of the pipe?
- A. SELECT FROM SYSTEM$PIPE_STATUS (''test.'extract'.my_pipe"i:
- B. SELECT FROM SYSTEM$PIPE_STATUS (,test.,,Extracr,,.ny_pipe, i I
- C. SELE2T * FROM SYSTEM$PIPE_STATUS < ' tes
- D. "Extract", my_pipe');
- E. SELECT * FROM SYSTEM$PIPE_STATUS ("tes
- F. 'extract' .my_pipe"};
Answer: C
Explanation:
The query that will provide the status of the pipe is SELECT * FROM SYSTEM$PIPE_STATUS(‘test.“Extract”.my_pipe’);. The SYSTEM$PIPE_STATUS function returns information about a pipe, such as its name, status, last received message timestamp, etc. The function takes one argument: the pipe name in a qualified form. The pipe name should include the database name, the schema name, and the pipe name, separated by dots. If any of these names are case-sensitive identifiers, they should be enclosed in double quotes. In this case, the schema name Extract is case-sensitive and should be quoted. The other options are incorrect because they do not follow the correct syntax for the pipe name argument. Option A and B use single quotes instead of double quotes for case-sensitive identifiers. Option D uses double quotes instead of single quotes for non-case-sensitive identifiers.
NEW QUESTION 4
A stream called TRANSACTIONS_STM is created on top of a transactions table in a continuous pipeline running in Snowflake. After a couple of months, the TRANSACTIONS table is renamed transactiok3_raw to comply with new naming standards
What will happen to the TRANSACTIONS _STM object?
- A. TRANSACTIONS _STMwill keep working as expected
- B. TRANSACTIONS _STMwill be stale and will need to be re-created
- C. TRANSACTIONS _STMwill be automatically renamedTRANSACTIONS _RAW_STM.
- D. Reading from the traksactioks_3T>: stream will succeed for some time after the expected STALE_TIME.
Answer: B
Explanation:
A stream is a Snowflake object that records the history of changes made to a table. A stream is associated with a specific table at the time of creation, and it cannot be altered to point to a different table later. Therefore, if the source table is renamed, the stream will become stale and will need to be re-created with the new table name. The other options are not correct because:
✑ TRANSACTIONS _STM will not keep working as expected, as it will lose track of
the changes made to the renamed table.
✑ TRANSACTIONS _STM will not be automatically renamed TRANSACTIONS
_RAW_STM, as streams do not inherit the name changes of their source tables.
✑ Reading from the transactions_stm stream will not succeed for some time after the expected STALE_TIME, as streams do not have a STALE_TIME property.
NEW QUESTION 5
The following chart represents the performance of a virtual warehouse over time: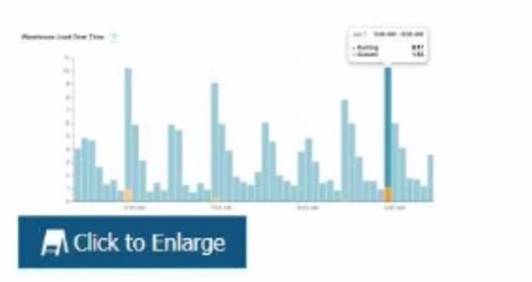
A DataEngineer notices that the warehouse is queueing queries The warehouse is size X- Smallthe minimum and maximum cluster counts are set to 1 the scaling policy is set to i and auto-suspend is set to 10 minutes.
How canthe performance be improved?
- A. Change the cluster settings
- B. Increase the size of the warehouse
- C. Change the scaling policy to economy
- D. Change auto-suspend to a longer time frame
Answer: B
Explanation:
The performance can be improved by increasing the size of the warehouse. The chart shows that the warehouse is queueing queries, which means that there are more queries than the warehouse can handle at its current size. Increasing the size of the warehouse will increase its processing power and concurrency limit, which could reduce the queueing time and improve the performance. The other options are not likely to improve the performance significantly. Option A, changing the cluster settings, will not help unless the minimum and maximum cluster countsare increased to allow for multi-cluster scaling. Option C, changing the scaling policy to economy, will not help because it will reduce the responsiveness of the warehouse to scale up or down based on demand. Option D, changing auto-suspend to a longer time frame, will not help because it will only affect how long the warehouse stays idle before suspending itself.
NEW QUESTION 6
Which query will show a list of the 20 most recent executions of a specified task kttask, that have been scheduled within the last hour that have ended or are stillrunning’s.
A)
B)
C)
D)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: B
NEW QUESTION 7
A database contains a table and a stored procedure defined as.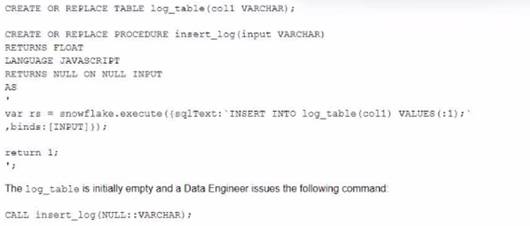
No other operations are affecting the log_table. What will be the outcome of the procedure call?
- A. The Iog_table contains zero records and the stored procedure returned 1 as a return value
- B. The Iog_table contains one record and the stored procedure returned 1 as a return value
- C. The log_table contains one record and the stored procedure returned NULL as a return value
- D. The Iog_table contains zero records and the stored procedure returned NULL as a return value
Answer: B
Explanation:
The stored procedure is defined with a FLOAT return type and a JavaScript language. The body of the stored procedure contains a SQL statement that inserts a row into the log_table with a value of ‘1’ for col1. The body also contains a return statement that returns 1 as a float value. When the stored procedure is called with any VARCHAR parameter, it will execute successfully and insert one record into the log_table and return 1 as a return value. The other options are not correct because:
✑ The log_table will not be empty after the stored procedure call, as it will contain
one record inserted by the SQL statement.
✑ The stored procedure will not return NULL as a return value, as it has an explicit return statement that returns 1.
NEW QUESTION 8
Which Snowflake objects does the Snowflake Kafka connector use? (Select THREE).
- A. Pipe
- B. Serverless task
- C. Internal user stage
- D. Internal table stage
- E. Internal named stage
- F. Storage integration
Answer: ADE
Explanation:
The Snowflake Kafka connector uses three Snowflake objects: pipe, internal table stage, and internal named stage. The pipe object is used to load data from an external stage into a Snowflake table using COPY statements. The internal table stage is used to store files that are loaded from Kafka topics into Snowflake using PUT commands. The internal named stage is used to store files that are rejected by the COPY statements due to errors or invalid data. The other options are not objects that are used by the Snowflake Kafka connector. Option B, serverless task, is an object that can execute SQL statements on a schedule without requiring a warehouse. Option C, internal user stage, is an object that can store files for a specific user in Snowflake using PUT commands. Option F, storage integration, is an object that can enable secure access to external cloud storage services without exposing credentials.
NEW QUESTION 9
What is the purpose of the BUILD_FILE_URL function in Snowflake?
- A. It generates an encrypted URL foe accessing a file in a stage.
- B. It generates a staged URL for accessing a file in a stage.
- C. It generates a permanent URL for accessing files in a stage.
- D. It generates a temporary URL for accessing a file in a stage.
Answer: B
Explanation:
The BUILD_FILE_URL function in Snowflake generates a temporary URL for accessing a file in a stage. The function takes two arguments: the stage name and the file path. The generated URL is valid for 24 hours and can be used to download or view the file contents. The other options are incorrect because they do not describe the purpose of the BUILD_FILE_URL function.
NEW QUESTION 10
A Data Engineer has created table t1 with datatype VARIANT: create or replace table t1 (cl variant);
The Engineer has loaded the following JSON data set. which has information about 4 laptop models into the table:
The Engineer now wants to query that data set so that results are shown as normal structured data. The result should be 4 rows and 4 columns without the double quotes surrounding the data elements in the JSON data.
The result should be similar to the use case where the data was selected from a normal
relational table z2 where t2 has string data type columns model id. model, manufacturer, and =iccisi_r.an=. and is queried with the SQL clause select * from t2;
Which select command will produce the correct results?
A)
B)
C)
D)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: B
NEW QUESTION 11
A Data Engineer needs to know the details regarding the micro-partition layout for a table named invoice using a built-in function.
Which query will provide this information?
- A. SELECT SYSTEM$CLUSTERING_INTFORMATICII (‘Invoice' ) ;
- B. SELECT $CLUSTERXNG_INFQRMATION ('Invoice')'
- C. CALL SYSTEM$CLUSTERING_INFORMATION (‘Invoice’);
- D. CALL $CLUSTERINS_INFORMATION('Invoice’);
Answer: A
Explanation:
The query that will provide information about the micro-partition layout for a table named invoice using a built-in function is SELECT SYSTEM$CLUSTERING_INFORMATION(‘Invoice’);. The
SYSTEM$CLUSTERING_INFORMATION function returns information about the clustering status of a table, such as the clustering key, the clustering depth, the clustering ratio, the partition count, etc. The function takes one argument: the table name in a qualified or unqualified form. In this case, the table name is Invoice and it is unqualified, which means that it will use the current database and schema as the context. The other options are incorrect because they do not use a valid built-in function for providing information about the micro-partition layout for a table. Option B is incorrect because it uses
$CLUSTERING_INFORMATION instead of SYSTEM$CLUSTERING_INFORMATION,
which is not a valid function name. Option C is incorrect because it uses CALL instead of SELECT, which is not a valid way to invoke a table function. Option D is incorrect because it uses CALL instead of SELECT and $CLUSTERING_INFORMATION instead of SYSTEM$CLUSTERING_INFORMATION, which are both invalid.
NEW QUESTION 12
What is a characteristic of the operations of streams in Snowflake?
- A. Whenever a stream is queried, the offset is automatically advanced.
- B. When a stream is used to update a target table the offset is advanced to the current time.
- C. Querying a stream returns all change records and table rows from the current offset to the current time.
- D. Each committed and uncommitted transaction on the source table automatically puts a change record in the stream.
Answer: C
Explanation:
A stream is a Snowflake object that records the history of changes made to a
table. A stream has an offset, which is a point in time that marks the beginning of the change records to be returned by the stream. Querying a stream returns all change records and table rows from the current offset to the current time. The offset is not automatically advanced by querying the stream, but it can be manually advanced by using the ALTER STREAM command. When a stream is used to update a target table, the offset is advanced to the current time only if the ON UPDATE clause is specified in the stream definition. Each committed transaction on the source table automatically puts a change record in the stream, but uncommitted transactions do not.
NEW QUESTION 13
Which methods will trigger an action that will evaluate a DataFrame? (Select TWO)
- A. DataFrame.random_split ( )
- B. DataFrame.collect ()
- C. DateFrame.select ()
- D. DataFrame.col ( )
- E. DataFrame.show ()
Answer: BE
Explanation:
The methods that will trigger an action that will evaluate a DataFrame are DataFrame.collect() and DataFrame.show(). These methods will force the execution of any pending transformations on the DataFrame and return or display the results. The other options are not methods that will evaluate a DataFrame. Option A, DataFrame.random_split(), is a method that will split a DataFrame into two or more DataFrames based on random weights. Option C, DataFrame.select(), is a method that will project a set of expressions on a DataFrame and return a new DataFrame. Option D, DataFrame.col(), is a method that will return a Column object based on a column name in a DataFrame.
NEW QUESTION 14
The following code is executed ina Snowflake environment with the default settings:
What will be the result of the select statement?
- A. SQL compilation error object CUSTOMER' does not exist or is not authorized.
- B. John
- C. 1
- D. 1John
Answer: C
NEW QUESTION 15
A Data Engineer needs to ingest invoice data in PDF format into Snowflake so that the data can be queried and used in a forecasting solution.
..... recommended way to ingest this data?
- A. Use Snowpipe to ingest the files that land in an external stage into a Snowflake table
- B. Use a COPY INTO command to ingest the PDF files in an external stage into a Snowflake table with a VARIANT column.
- C. Create an external table on the PDF files that are stored in a stage and parse the data nto structured data
- D. Create a Java User-Defined Function (UDF) that leverages Java-based PDF parser libraries to parse PDF data into structured data
Answer: D
Explanation:
The recommended way to ingest invoice data in PDF format into Snowflake
is to create a Java User-Defined Function (UDF) that leverages Java-based PDF parser libraries to parse PDF data into structured data. This option allows for more flexibility and control over how the PDF data is extracted and transformed. The other options are not suitable for ingesting PDF data into Snowflake. Option A and B are incorrect because Snowpipe and COPY INTO commands can only ingest files that are in supported file formats, such as CSV, JSON, XML, etc. PDF files are not supported by Snowflake and will cause errors or unexpected results. Option C is incorrect because external tables can only query files that are in supported file formats as well. PDF files cannot be parsed by external tables and will cause errors or unexpected results.
NEW QUESTION 16
A secure function returns data coming through an inbound share
What will happen if a Data Engineer tries to assign usage privileges on this function to an outbound share?
- A. An error will be returned because the Engineer cannot share data that has already been shared
- B. An error will be returned because only views and secure stored procedures can be shared
- C. An error will be returned because only secure functions can be shared with inboundshares
- D. The Engineer will be able to share the secure function with other accounts
Answer: A
Explanation:
An error will be returned because the Engineer cannot share data that has already been shared. A secure function is a Snowflake function that can access data from an inbound share, which is a share that is created by another account and consumed by the current account. A secure function can only be shared with an inbound share, not an outbound share, which is a share that is created by the current account and shared with other accounts. This is to prevent data leakage or unauthorized access to the data from the inbound share.
NEW QUESTION 17
Which callback function is required within a JavaScript User-Defined Function (UDF) for it to execute successfully?
- A. initialize ()
- B. processRow ()
- C. handler
- D. finalize ()
Answer: B
Explanation:
The processRow () callback function is required within a JavaScript UDF for it to execute successfully. This function defines how each row of input data is processed and what output is returned. The other callback functions are optional and can be used for initialization, finalization, or error handling.
NEW QUESTION 18
......
100% Valid and Newest Version DEA-C01 Questions & Answers shared by Downloadfreepdf.net, Get Full Dumps HERE: https://www.downloadfreepdf.net/DEA-C01-pdf-download.html (New 65 Q&As)